

关注并星标
从此不迷路
公众号ID|ComputerVisionGzq
学习群|扫码在主页获取加入方式
计算机视觉研究院专栏
作者:Edison_G
当 CPU 图像预处理成为视觉任务的瓶颈,最新开源的CV-CUDA,将为图像预处理算子提速百倍。
转自《机器之心》
以图像背景模糊算法为例,将CV-CUDA替换 OpenCV作为图像预/后处理的后端,整个推理过程吞吐量能加20 多倍。
如果小伙伴们想试试更快、更好用的视觉预处理库,可以试试这一开源工具。
开源地址:https://github.com/CVCUDA/CV-CUDA
图像预/后处理已成为 CV 瓶颈
以图像背景模糊算法为例,常规的图像处理流程中预\后处理主要在 CPU 完成,占据整体 90% 的工作负载,其已经成为该任务的瓶颈。
-
部分算子的 CPU 和 GPU 结果精度无法对齐;
-
部分算子 GPU 性能比 CPU 性能还弱;
-
同时存在各种CPU算子与各种 GPU 算子,当处理流程需要同时使用两种,就额外增加了内存与显存中的空间申请与数据迁移/数据拷贝;
完全在 GPU 上进行预处理与后处理,将大大降低图像处理部分的CPU 瓶颈。
正如前文的背景模糊吞吐量加速比图,如果采用CV-CUDA 替代 OpenCV 和 TorchVision 的前后处理后,整个推理流程的吞吐率提升20 多倍。其中预处理对图像做 Resize、Padding、Image2Tensor 等操作,后处理对预测结果做的Tensor2Mask、Crop、Resize、Denoise 等操作。
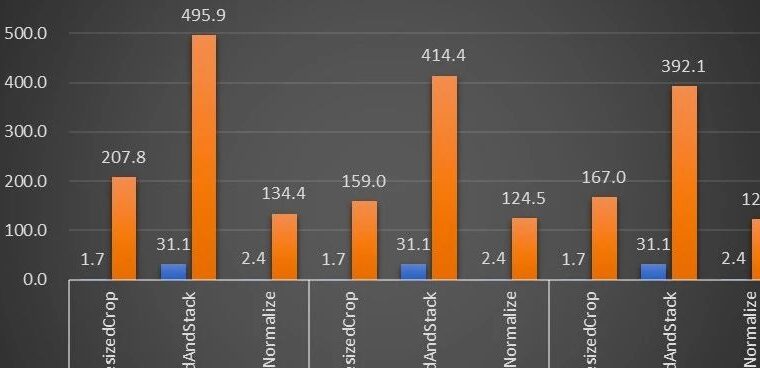
在同一个计算节点上(2x Intel Xeon Platinum 8168 CPUs,1x NVIDIA A100 GPU),以 30fps 的帧率处理 1080p 视频,采用不同 CV 库所能支持的最大的并行流数。测试采用了 4 个进程,每个进程 batchSize 为 64。
对于单个算子的性能,NVIDIA和字节跳动的小伙伴也做了性能测试,很多算子在GPU 上的吞吐量能达到 CPU 的百倍。
图片大小为 480*360,CPU 选择为 Intel(R) Core(TM) i9-7900X,BatchSize 大小为 1,进程数为 1
此外,因为CV-CUDA同时拥有 C++接口与 Python 接口,它能同时用于训练与服务部署场景,在训练时用Python 接口跟快速地验证模型能力,在部署时利用C++接口进行更高效地预测。CV-CUDA免于繁琐的预处理结果对齐过程,提高了整体流程的效率。
CV-CUDA进行 Resize 的 C++接口
实战,CV-CUDA怎么用
常规图像识别的预处理流程,使用CV-CUDA将会把预处理过程与模型计算都统一放在GPU 上运行。
如下在使用 torchvision 的 API 加载图片到 GPU之后,Torch Tensor 类型能直接通过 as_tensor 转化为CV-CUDA 对象 nvcvInputTensor,这样就能直接调用CV-CUDA 预处理操作的 API,在 GPU 中完成对图像的各种变换。
如下几行代码将借助 CV-CUDA 在 GPU 中完成图像识别的预处理过程:裁剪图像并对像素进行归一化。其中resize() 将图像张量转化为模型的输入张量尺寸;convertto()将像素值转化为单精度浮点值;normalize()将归一化像素值,以令取值范围更适合模型进行训练。
CV-CUDA 各种预处理操作的使用与 OpenCV 或 Torchvision中的不会有太大区别,只不过简单调个方法,其背后就已经在 GPU 上完成运算了。
现在借助借助 CV-CUDA 的各种 API,图像分类任务的预处理已经都做完了,其能高效地在GPU 上完成并行计算,并很方便地融合到PyTorch 这类主流深度学习框架的建模流程中。剩下的,只需要将CV-CUDA对象nvcvPreprocessedTensor 转化为Torch Tensor 类型就能馈送到模型了,这一步同样很简单,转换只需一行代码:
通过这个简单的例子,很容易发现CV-CUDA 确实很容易就嵌入到正常的模型训练逻辑中。如果读者希望了解更多的使用细节,还是可以查阅前文CV-CUDA的开源地址。
CV-CUDA对实际业务的提升
CV-CUDA实际上已经经过了实际业务上的检验。在视觉任务,尤其是图像有比较复杂的预处理过程的任务,利用 GPU 庞大的算力进行预处理,能有效提神模型训练与推理的效率。CV-CUDA 目前在抖音集团内部的多个线上线下场景得到了应用,比如搜索多模态,图片分类等。
字节跳动机器学习团队表示,CV-CUDA 在内部的使用能显著提升训练与推理的性能。例如在训练方面,字节跳动一个视频相关的多模态任务,其预处理部分既有多帧视频的解码,也有很多的数据增强,导致这部分逻辑很复杂。复杂的预处理逻辑导致 CPU 多核性能在训练时仍然跟不上,因此采用CV-CUDA将所有 CPU 上的预处理逻辑迁移到 GPU,整体训练速度上获得了 90%的加速。注意这可是整体训练速度上的提升,而不只是预处理部分的提速。
在字节跳动 OCR 与视频多模态任务上,通过使用CV-CUDA,整体训练速度能提升 1 到 2 倍(注意:是模型整体训练速度的提升)
在推理过程也一样,字节跳动机器学习团队表示,在一个搜索多模态任务中使用 CV-CUDA 后,整体的上线吞吐量相比于用 CPU 做预处理时有了 2 倍多的提升。值得注意的是,这里的 CPU基线结果本来就经过多核高度优化,并且该任务涉及到的预处理逻辑较简单,但使用 CV-CUDA 之后加速效果依然非常明显。
速度上足够高效以打破视觉任务中的预处理瓶颈,再加上使用也简单灵活,CV-CUDA 已经证明了在实际应用场景中能很大程度地提升模型推理与训练效果,所以要是读者们的视觉任务同样受限于预处理效率,那就试试最新开源的CV-CUDA吧。
转载请联系本公众号获得授权
计算机视觉研究院学习群等你加入!
ABOUT
计算机视觉研究院
VX:2311123606
往
期
推
荐
本文来自微信公众号“计算机视觉研究院”(ID:ComputerVisionGzq)。大作社经授权转载,该文观点仅代表作者本人,大作社平台仅提供信息存储空间服务。









