

本文是
MixNet、MobileNetV3、MnasNet、EfficientNet、EfficientDet等论文作者Tan Mingxing(就职于谷歌)在NAS目标领域的又一力作。
Abstract
Inverted bottleneck layers, IBN已成为终端设备SOTA目标检测方法的主要模块。而在这片文章里,作者通过重新分析研究终端芯片加速下的常规卷积而对“IBN主导的网络架构是否最优”提出了质疑。作者通过将常规卷积纳入搜索空间取得了延迟-精度均衡下的性能提升,得到了一类目标检测模型:MobileDets。在COCO目标检测任务上,基于同等终端CPU推理延迟,MobileDets以1.7mAP性能优于MobileNetV3+SSDLite,以1.9mAP性能优于MobileNetV2+SSDLite;在EdgeTPU平台上,以3.7mAP性能优于MobileNetV2+SSDLite且推理更快;在DSP平台上,以3.4mAP性能优于MobileNetV2+SSDLite且推理更快。与此同时,在不采用FPN的情况下,在终端CPU平台,MobileDets取得了媲美MnasFPN的性能;在EdgeTPU与DSP平台具有更优的mAP指标,同时推理速度快2倍。
Introduction
截止目前,NAS已成功了搜索到大量具有高性能且适合于特定硬件平台的的模型,比如MobileNetV3、MixNet、EfficientNet、FALSR等等,其中分类模型往往以Inverted bottlenecl作为核心关键模块。由于IBN模块中的深度分离算卷积特性,IBN擅长于减少参数量与FLOPS,同时深度分离卷积极为适合于终端CPU。尽管如此,深度分离卷积对于当前终端芯片的适配性往往并非最优,比如在EdgeTPU与高通DSP上,具有特定形状的Tensor与核维度的常规卷积往往具有比深度分离卷积更快的速度(甚至高达3倍),尽管具有更多的FLOPS(理论计算复杂度与实际推理速度不成成正比)。
It is observed that for certain tensor shapes and kernel dimensions, a regular convolution can utilize the hardware up to 3x mor efficiently than the depthwise variation on an EdgeTPU despite the much larger amount of theoretical computation cost(7x more FLOPS).
基于上述现象,作者提出一个扩大的搜索空间:包含IBN与受启发于Tensor Decomposition的全卷积序列,称之为Tensor Decomposition Based Search Space(TBD),它可以跨不同终端芯片应用。作者以CPU、EdgeTPU、DSP硬件平台为蓝本,在目标检测任务上采用NAS方式进行网络架构设计。仅仅采用一种简单的SSDLite进行目标检测架构组成,所设计的网络架构称之为MobileDets,在同等推理延迟约束下,它以1.9mAP@CPU、3.7mAP@EdgeTPU、3.4mAP@DSP优于MobileNetV2,同时它以1.7mAP@CPU优于MobileNetV3。与此同时,在未采用NAS-FPN的条件下,取得了媲美此前终端SOTA方法MnasFPN的性能且具有更快的推理速度(在EdgeTPU、DSP上快2倍)。
本文的贡献主要包含以下几点:
-
证实:广泛采用的 IBN-only的搜索空间对于EdgeTPU、DSP等终端加速芯片平台是次优的;
-
提出一种新颖的搜索空间: TBD,它适用于不同的终端加速芯片;
-
证实:如何采用NAS工具为不同的加速硬件平台挖掘具有高性能的网络架构;
-
取得了一类具有SOTA性能的方法: MobileDets。
Revisiting Full Convs in Mobile Search Spaces
在这部分内容中,作者首先解释为何IBN不合适于终端CPU外的其他终端加速器?;然后提出一种新的基于常规卷积的模块用于扩充搜索空间;最后讨论了所设计的模块与Tucker/TP分解之间的关联性。
IBNs are all we need? IBN模块常用于降低参数量与FLOPS,并利用深度分离卷积去的终端CPU平台的推理加速。然而,在其他终端加速器(如EdgeTPU、DSP)上,尽管具有更多的FLOPS,常规卷积往往比深度分离卷积更快(3x)。这意味着之前广泛采用IBN搜索空间对于其他终端加速器并非最优。鉴于此,作者提出两种用于通道扩展和压缩的灵活层。
Fused Inverted Bottleneck Layers
深度分离卷积是IBN的重要组成成分,其背后核心思想:采用深度卷积+1x1point卷积替换expensive的全卷积(即常规卷积)。但是这种expensive的评价源自于FLOPS或者参数量,而非实际硬件平台的推理速度。
为更红的集成常规卷积,作者提出融合IBN中的第一个1x1卷积(往往用于通道扩展)与深度卷积,见上图。作者将这种改进后的模块称之为Fused Convolution Layers。
Generalied Bottleneck Layers
Bottleneck首次是由ResNet引入并用于降低高维特征的计算量,它采用两个1x1卷积进行通道降维与升维。Bottleneck有助于在更细粒度层面控制通道大小(通道大小将直接影响推理延迟),在此基础上,作者引入两个压缩比例系数对其进行了扩展,整体架构见下图。作者将这种改进后的模块称之为Tucker Convolution.
Connections with Tucker/CP Decomposition
CP分解采用1x1point卷积、深度卷积、1x1point卷积等操作对卷积进行近似;而mode-2的Tucker分解则采用1x1卷积、
卷积、1x1卷积进行近似。
作者认为前述所设计的模块均可与Tucker/CP分解存在关联,Fig.2给出了IBN的网络架构示意图,它等价于常规卷积的CP分解;Fig.3中的Tucker模块等价于常规卷积的Tucker分解;Fig。4中的Fused模块可是为Tucker分解的变种。
因此,作者将扩展操作称之为Fused卷积,压缩操作称之为Tucker,而所设计的搜索空间称之为Tucker Decomposition based Search Space.
本人对于如何采用NAS进行网络架构的搜索兴趣不大,也没有足够的GPU/TPU去从头开始搜索,故而关于NAS部分的内容略过,感兴趣的小伙伴们请自行查看原文。
Experiments
Standalone Training 作者采用
大小的图像进行训练与验证,训练的硬件平台:32 synchronized replicas on a 4x4 TPU-v2 Pod(土豪行为,反正我是从来没用过这么的资源,极度羡慕啊)。同时为更公平的与其他方法进行对比,作者采用TensorFlow目标检测API中的标准预处理操作而未采用其他增强操作(如drop-block、auto-augment)。训练优化器选用SGD,动量因子为0.9,权重衰减因子为
。所有模型从头开始训练而未在ImageNet上进行预训练,同时考虑了下面两种训练机制:
-
Short-schedule:每个模型训练50K步,batchsize=1024,初始学习率为4.0(这里的学习率确定没有问题吗?);
-
Long-schedule:每个模型训练400K步,batchsize=512,初始学习率为0.8。
Latency Benchmarking
作者采用TF-Lite(它依赖于NNAPI进行计算加速)作为基准,在所有基准测试中,作者采用单线程、batchsize=1。在CPU端,仅需一个大的CPU核即可,而在EdgeTPU、DSP端,所有模型需要进行fake-quantized。
Search Space Definitions
在搜索空间方面,作者设计了下面三种形式:
-
IBN:它是最小的搜索空间,仅仅包含IBN。卷积核尺寸可选范围(3、5),扩展因子可选范围(4、8);
-
IBN+Fused:它即包含IBN,同时包含Fused模块。卷积和与扩展因子参数同上;
-
IBN+Fused+Tucker:它为最大的搜索空间,包含IBN、Fused模块以及Tucker模块。Tucker的压缩因子可选范围(0.25、0.75)。
Hardware-Specific Adaptations 前面所提到的搜索空间还会因硬件平台而进行些微调整。
-
当适配平台为CPU时,前述所有模块采用 Squeeze-and-Excitation进行增广,同时采用h-swish作为激活函数替代ReLU6,这是为了更公平的与MobileNetV3+SSDLite进行对比。而所提到的两者并不适合与EdgeTPU与DSP平台;
-
当适配平台为DSP时,搜索空间应剔除5x5卷积,因硬件约束导致极为低效。
Search Space Ablation
对于不同硬件平台(CPU、EdgeTPU、DSP),作者采用不同的搜索空间变种进行架构搜索并从头开始训练进行评估。目标在于:验证不同搜索空间的有效性。
CPU 下图给出了Pixel-1 CPU平台下所搜索到的网络性能与MobileNetV3+SSDLite的性能对比。从中可以看到:在这种情况下,常规卷积并没能提供明显的优势。尽管如此,域相关的架构搜索在150-200ms约束的模型仍具有1mAP的性能增益。
EdgeTPU 下图给出了Pixel-4 EdgeTPU平台下所搜索到的网络性能域MobileNetV2+SSDLite的性能对比。从中可以看到:三种搜索空间下的架构均具有极大的性能改进。这主要源于baseline采用的MobileNetV2主要是针对CPU进行的优化,与EdgeTPU并非最佳相关。尽管IBN-only可以取得最佳精度-MAdds均衡,带有常规卷积的搜索空间仍能看到明显的优势。上述结果从实验角度证实了:全卷积在EdgeTPU端的有效性。
DSP 下图给出了Pixel-4 EdgeTPU平台下所搜索到的网络性能域MobileNetV2+SSDLite的性能对比。类似于EdgeTPU情况,可以看到:域相关的NAS可以得到明显的性能提升。同时,在同等推理延迟下,常规卷积可以产生mAP性能提升。
Main Results
作者在COCO数据集上对所设计的网路架构进行性能对比,相关结果见下表。
从上表可以看到:
-
终端CPU:(1)在同等推理延迟下,MobileDet以1.7mAP指标优于MobileNetV3+SSDLite;(2)在不采用NAS-FPN的情况下,取得了媲美MnasFPN的性能。由此可以看出: IBN确实是适用于终端CPU平台的模块。
-
EdgeTPU:在同等推理延迟下,MobileDet以3.7mAP指标优于MobileNetV2+SSDLite。这种性能增益源自:域相关NAS、全卷积序列模块(Fused、Tucker)。
-
DSP:(1)MobileDet取得28.5mAP@12.ms的性能,以3.2mAP指标优于MobileNetV2+SSDLite;(2)以2.4mAP指标优于MnasFPN,同时具有更快的推理速度。
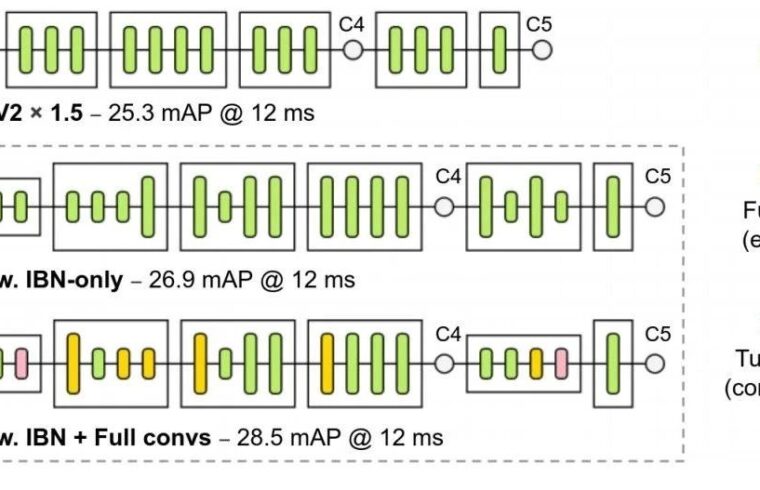
下图给出了所搜索到的网络架构示意图。从中可以看到一件有意思的发现:在EdgeTPU与DSP平台,MobileDet在网络早期(此时深度卷积倾向于低效)大量采用Fused等常规卷积。上述结果可以证实:IBN-only搜索空间对于这些加速硬件平台而言并非最优。
最后,作者还进行了跨硬件平台网络架构迁移性能测试,见下图。从中可以看到:(1)EdgeTPU与DSP约束下搜索的模型可以很好的相互迁移;(2)EdgeTPU与DSP约束下搜索的模型并不能很好的迁移到CPU端。
Conclusion
在该篇文章中,作者对主流的深度分离卷积主导的模块进行了质疑并提出了可行性的改进方案。以目标检测任务为基础,重新回顾并分析了常规卷积跨终端加速器(CPU、EdgeTPU、DSP)的有效性。结果表明:在不同终端设备加速平台,在网络的合适位置嵌入常规卷积可以取得精度-推理方面的性能提升。所得到的MobileDets在不同硬件平台下取得优异的检测结果,极大的优于此前方案。
本文来自微信公众号“AIWalker”(ID:happyaiwalker)。大作社经授权转载,该文观点仅代表作者本人,大作社平台仅提供信息存储空间服务。









